可以查詢一個中文字、中文字串、英文拆碼(可含萬用字元 * 和 ?)
也可以查詢 CNS (如 1-6E65 或 15-432F) 或 Unicode (如 U+8766)
也可以查詢 CNS (如 1-6E65 或 15-432F) 或 Unicode (如 U+8766)

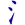


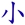

 本身就是一個簡速字根 T,所以 額 也可以拆成 NPOT,取頭尾碼就是 NT,這是額拆成 NT 的原意。
本身就是一個簡速字根 T,所以 額 也可以拆成 NPOT,取頭尾碼就是 NT,這是額拆成 NT 的原意。
 ,只不過兩邊被拆開了。
,只不過兩邊被拆開了。 本身就是一個字根 S
本身就是一個字根 S 也是一個字根 S
也是一個字根 S 更狠,本身就是一個字根 E。
更狠,本身就是一個字根 E。「第」的標準拆法是 ZQIP,
Z 
Q 
I 
P 
卡就是
F -> 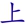
P ->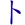
A -> 補根 
這個字很簡單
E -> 
E ->
R -> 
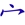

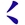

 本身就是一個字根,所以要拆成 而不是
本身就是一個字根,所以要拆成 而不是