可以查詢一個中文字、中文字串、英文拆碼(可含萬用字元 * 和 ?)
也可以查詢 CNS (如 1-6E65 或 15-432F) 或 Unicode (如 U+8766)
也可以查詢 CNS (如 1-6E65 或 15-432F) 或 Unicode (如 U+8766)

 」的最佳解說( 最後更新: 2009-06-24 18:19:24, id# 189 )
」的最佳解說( 最後更新: 2009-06-24 18:19:24, id# 189 )
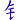 ,它其實是 金 的簡體字,所以拆碼是 A
,它其實是 金 的簡體字,所以拆碼是 A
 」的最佳解說( 最後更新: 2009-06-23 11:31:54, id# 185 )
」的最佳解說( 最後更新: 2009-06-23 11:31:54, id# 185 )




 S ->
S ->  L -> 補根
L -> 補根 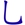
 ,所以補根就變成 N 了。當然,建議大家還是使用 GSL 比較好,這才是正確的寫法。
,所以補根就變成 N 了。當然,建議大家還是使用 GSL 比較好,這才是正確的寫法。 A ->
A ->  D ->
D ->  F ->
F -> 
 是一個簡速字根 J F -> A -> 補根 是一個字根,就會把 拆成
是一個簡速字根 J F -> A -> 補根 是一個字根,就會把 拆成 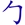
 或是
或是 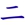 ,這畢竟不是標準拆法,非常不建議使用。 寫成
,這畢竟不是標準拆法,非常不建議使用。 寫成  的容錯拆法,同樣不建議使用。
的容錯拆法,同樣不建議使用。 O ->
O ->  S ->
S -> 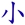 K ->
K -> 
 本身是一個簡速字根 G L -> 補根
本身是一個簡速字根 G L -> 補根  是簡速字根 L ,所以原本的 LO 就變成了 L
是簡速字根 L ,所以原本的 LO 就變成了 L ,O 就變成了 H。當然,非常不建議採用這種拆法,這只是容錯而已。
,O 就變成了 H。當然,非常不建議採用這種拆法,這只是容錯而已。 A -> Q ->
A -> Q ->  E ->
E -> 
 本身是一個簡速字根 H H -> E -> 補根 K ->
本身是一個簡速字根 H H -> E -> 補根 K ->  A ->
A -> 



這樣拆,然後由左至右,由上至下的順序。
所以是S J Q S